DistributedDataParallel non-floating point dtype parameter with
$ 31.50 · 4.6 (653) · In stock
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re

Sharded Data Parallelism - SageMaker
DistributedDataParallel don't work at nightly build(1.6.0.dev20200408+cu101) · Issue #36268 · pytorch/pytorch · GitHub

DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub

A comprehensive guide of Distributed Data Parallel (DDP), by François Porcher

LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language
Optimizing model performance, Cibin John Joseph

Does moxing.tensorflow Contain the Entire TensorFlow? How Do I Perform Local Fine Tune on the Generated Checkpoint?_ModelArts_Troubleshooting_MoXing
Parameter Server Distributed RPC example is limited to only one worker. · Issue #780 · pytorch/examples · GitHub
nll_loss doesn't support empty tensors on gpu · Issue #31472 · pytorch/pytorch · GitHub
fairscale/fairscale/nn/data_parallel/sharded_ddp.py at main · facebookresearch/fairscale · GitHub
Support DistributedDataParallel and DataParallel, and publish Python package · Issue #30 · InterDigitalInc/CompressAI · GitHub

55.4 [Train.py] Designing the input and the output pipelines - EN - Deep Learning Bible - 4. Object Detection - Eng.
distributed data parallel, gloo backend works, but nccl deadlock · Issue #17745 · pytorch/pytorch · GitHub
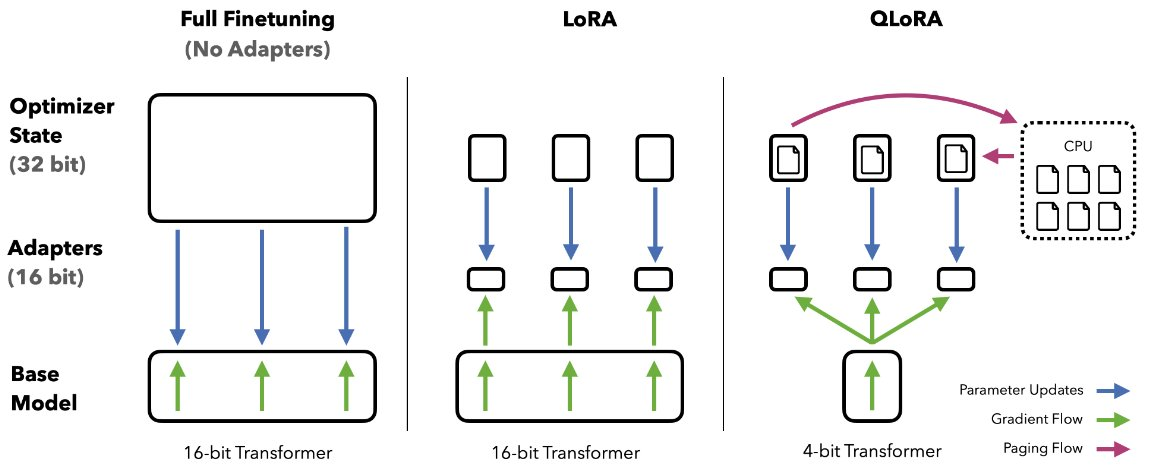
Finetune LLMs on your own consumer hardware using tools from PyTorch and Hugging Face ecosystem

Access Authenticated Using a Token_ModelArts_Model Inference_Deploying an AI Application as a Service_Deploying AI Applications as Real-Time Services_Accessing Real-Time Services_Authentication Mode