Spark Performance Optimization Series: #1. Skew
$ 10.50 · 4.7 (244) · In stock

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

How to Optimize Spark Applications for Performance using Sparklens

Kubernetes Architecture,Hands On!, by Himansu Sekhar

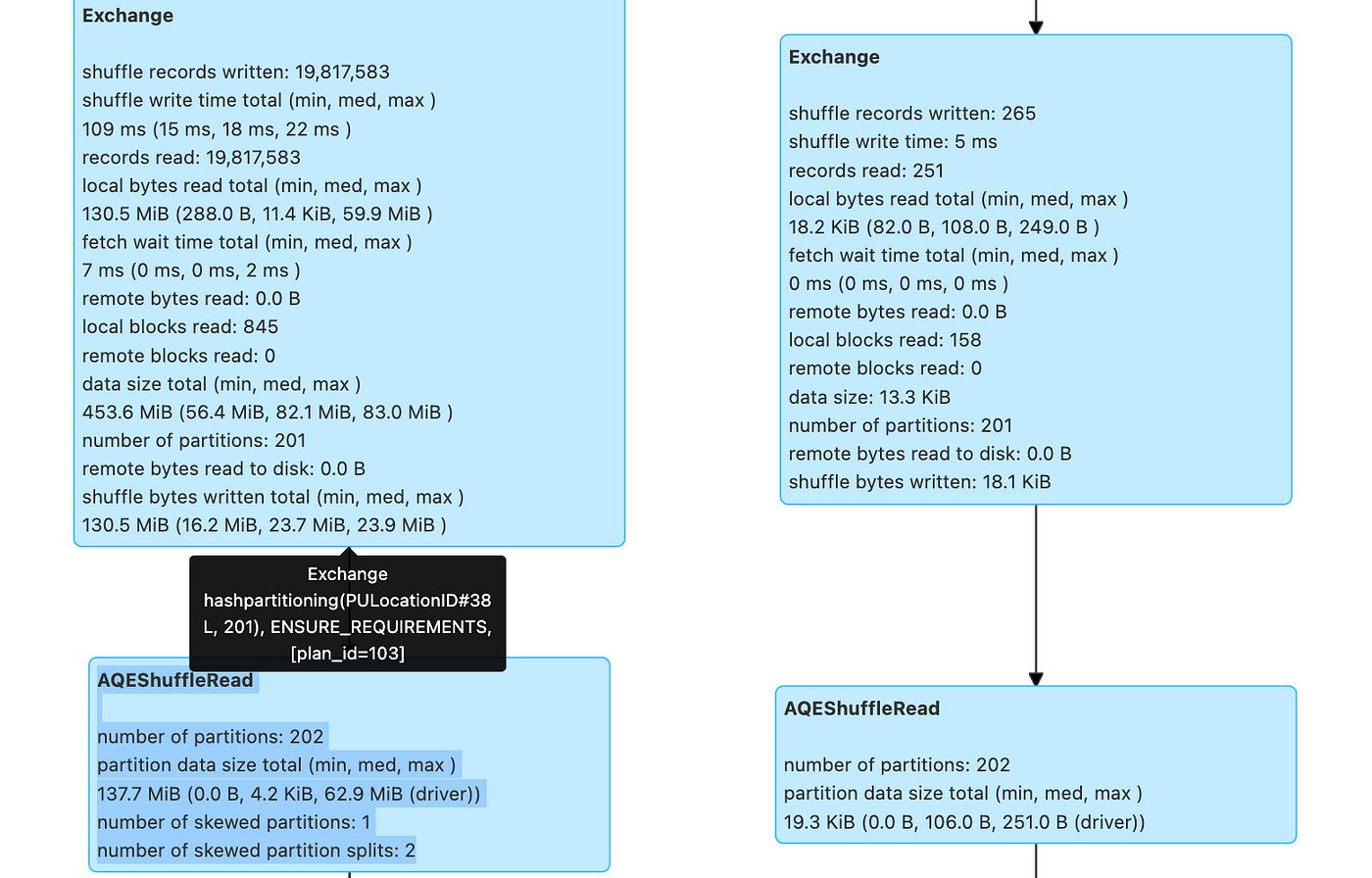
Partition Skew of Apache Spark

Using different partitioning methods in Spark to help with data skew - Cloud Fundis

i.ytimg.com/vi/d41_X78ojCg/sddefault.jpg
Handling Data Skew in Apache Spark: Techniques, Tips and Tricks to Improve Performance, by Suffyan Asad

Apache Spark Core—Deep Dive—Proper Optimization

Monitoring Apache Spark – We're building a better Spark UI - KDnuggets

Data-induced predicates for sideways information passing in query optimizers

List: Spark Optimization, Curated by Ashwin Krishnan
List: Reading list, Curated by mohit chaurasia
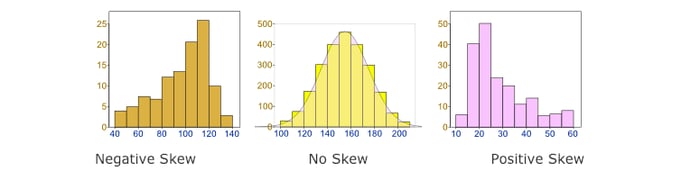
Optimizing the Skew in Spark

Handling Data Skew in Apache Spark: Techniques, Tips and Tricks to Improve Performance, by Suffyan Asad
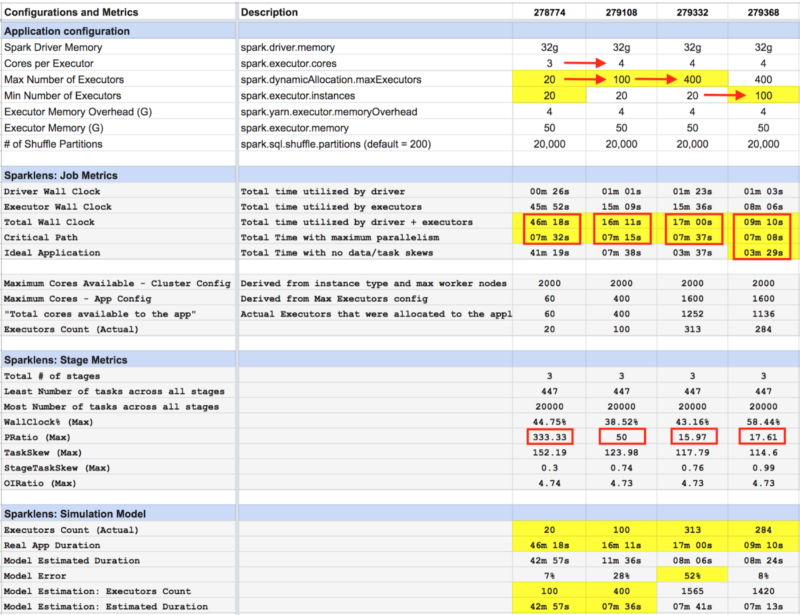
Spark Application Optimization for Performance using Qubole Sparklens